

In Part 1 I showed how to setup a simple TSA/HADR cluster, consisting of two servers, and what happens to an active client connection in case of a failover. You can read Part 1 here.
In this part we will first reconfigure the TSA/HADR cluster to use ACR and then retry the failover and observe its effects on the client connection.
TSA/HADR failover with ACR
With the TSA/HADR already setup in Part 1, it remains to setup the ACR (Automatic Client Reroute) feature of DB2 and see how it affects the client processing during and after a failover.
The ACR is configured on both servers as follows:
Primary (ITCHY, 192.168.20.64):

Standby (SCRATCHY, 192.168.20.65):

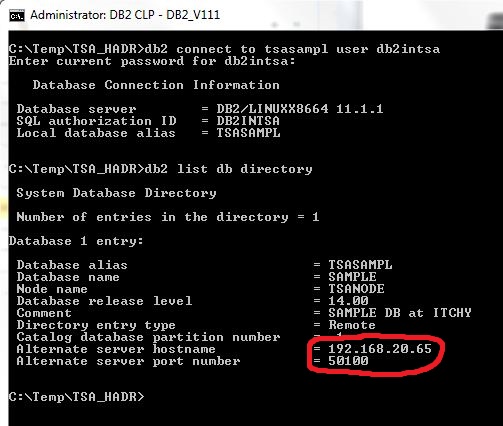
The change is visible on the client as soon as a connection to the database is established:
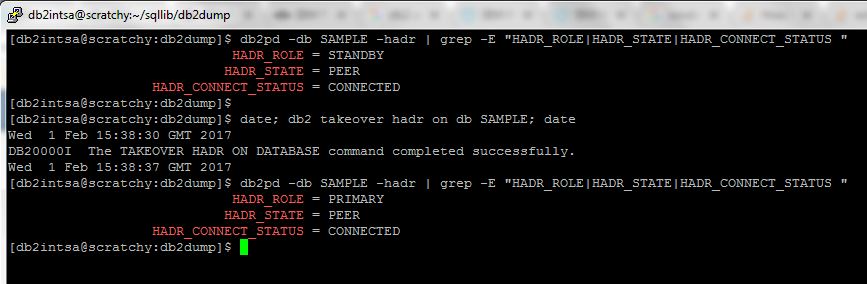
Executing the failover with ACR in place:
Now there is a different result on the client:
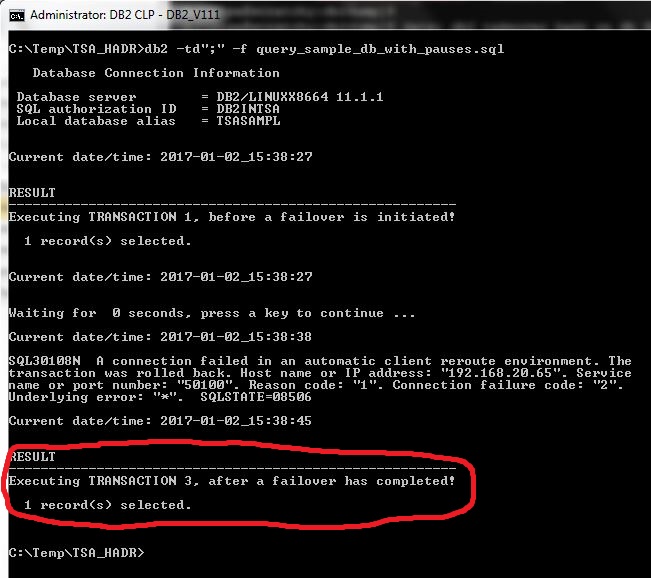
The first transaction succeeded, as before.
The second transaction failed, as before (ACR does not help here: “ACR does not replay in-flight transactions, and once the client connection is established, any uncommitted work will have to be performed”).
But here’s the change: the third transaction succeeded, without any need for user intervention nor batch job restart!
If we look at the client’s DB directory configuration, we can see the change to the alternate server configuration, which now points at ITCHY (also note now invalid Comment text, as the database is not on ITCHY anymore):
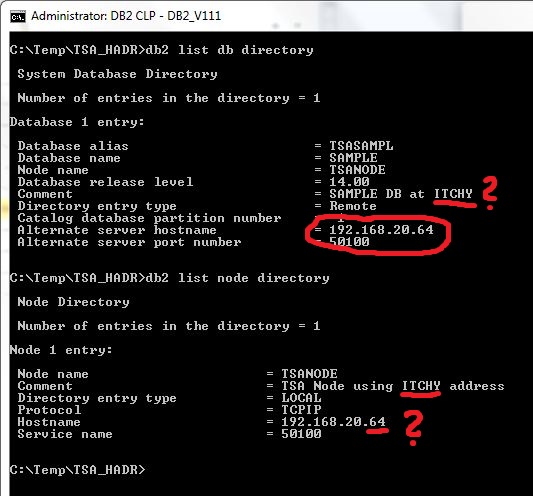
Interestingly, the TSANODE entry still seems to be pointing to ITCHY!
But, if we take a look at the established TCP/IP connections on the client, we can see that in reality the client is now connected to SCRATCHY (192.168.20.65), as expected:
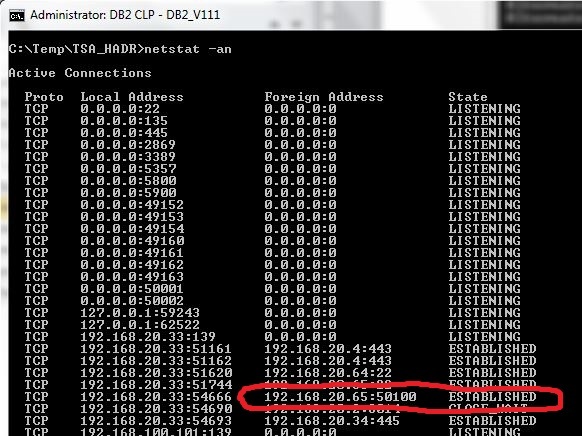
So then, what exactly is going on here??
Honestly, I have not (yet) found out… it seems as if not all of the DB2 configuration is updated/displayed properly in case of an ACR event!
Conclusion
Even with the displayed configuration quirk, thanks to ACR the client successfully (and automatically) recovered its database connection following a failover and resumed its batch job processing immediately.
From a client’s point of view, the business continuity was maintained, therefore this setup should be acceptable to the client.
From a network administrator’s point of view, there’s a bit more complexity involved with this design, because a client must be able to connect to all servers in the cluster (in this case, only two).
This could require additional configuration settings on the network equipment between the client and the server, such as routers, firewalls, etc.
In order to improve on these points, in the next parts of this series (Part 3 and Part 4) we will take a closer look at a TSA feature called VIP (“Virtual IP address”) and how it affects the active client connections, with or without ACR.