

In this two-part blog ‘Behind the Scenes with Foreign Keys’ I’m going to take a look at what Foreign Keys do “under-the covers” or, more accurately what some of the options available will do in combination with each other. Part 1 will examine some of the mechanics of this commonly-used (and, dare I say it, commonly misused) feature, and Part 2 will examine some of the performance implications.
It sounds as if this should be a fairly straightforward, black-and-white issue: you create a Foreign Key (FK in future, for the sake of brevity), this validates itself against your data and hey-presto, you have a Referential Integrity solution designed into your database which takes all the hassle of preventing the creation of, or removing orphan data, into an automated, behind the scenes feature. But what if your FK is “not enforced”? Or if its unchecked? Or has been disabled? How do you interrogate the state of these things and what are the implications?
Overview
Defining an FK (at the risk of explaining the obvious) is simply defining a constraint on a table such that it refers to a Parent. Comme ca
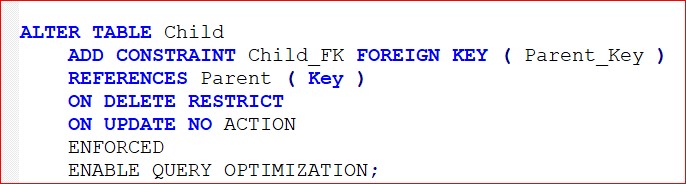
But there are a number of options in there (not all covered in that command) and you need to be able to see, at a glance, what they are set to and what the implications are. Many of them may mean one thing in isolation but something slightly different in combination with another. I use a view based on the system catalogues, with some of the flag values being translated into meaningful text, which will give an overview like this:


I’ve split this over 2 lines here, but any other examples will be condensed for brevity sake, to fit on one line. This, and all other relevant SQL, is available via a link in the Conclusion.
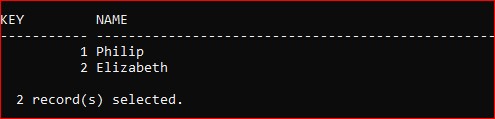
The test data I’m going to use to show the various options is a simple PARENT table containing just these 2 rows:
And a Child table containing these 4 rows:
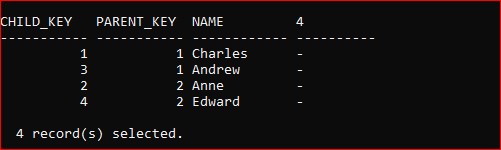
NB: anyone who thinks this is disrespectful to our Royal Family, I should point out that this is actually a family of Labrador retrievers owned by a neighbour of mine.
Letting invalid data in
So, this is exactly what FKs and Referential Integrity (RI) are supposed to avoid. But there are times when you might want the checks switched off: they are, of course, a performance overhead. You might need them switched off for maintenance (e.g. detaching partitions from a Range-Partitioned table). What are the options and the implications?
To start with, you can quite simply “switch off” the FK:

The effect on the FK can be seen with that view I used earlier:

NB: you can see that the “Trusted” value in now Y. It was before, really, but if the FK is Enforced then it is implicitly trusted, so the system catalogue (SYSCAT.TABCONST) stores it as a blank for “not applicable”.
The changes that I’ve highlighted are that the FK is no longer enforced (which is what I asked for) and that the data is now never checked (which I didn’t specifically ask for, but which is a logical outcome of that ALTER statement).
This means I can now insert data which has no parent:
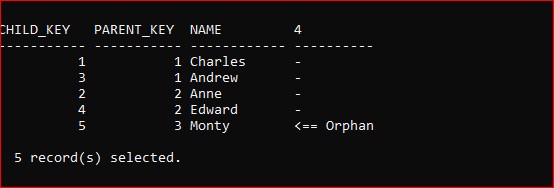
There might be valid reasons why I want to do that; maybe in a test environment to provoke a response from the application, but I can’t now switch the FK back on (set it ENFORCED) as it will recognize the orphan data situation:

NB: notice the error says it cannot be created even though it already exists and we’re just altering a switch.
Getting invalid data out
So, next step, how do we clean up our data? Pretty straight-forward here but imagine that we’re dealing with 1,000s maybe 1,000,000s of orphans. One way this can arise is the afore-mentioned partition detach; if you detach a partition and there are related tables with no corresponding partitions, you will have some cleaning up to do to keep the data in-line.
What we can do is

NB: I’ve specified READ ACCESS to show that, even when you try and force the FK into action again, you might find yourself stymied. The RI view shows the options that results from this latest command:

As we specified, the table is now in Integrity Pending status and Read-Only mode. That means we can SELECT from the table and see our existing orphan is still there, but that any attempt to modify (in this case, INSERT) data will fail:
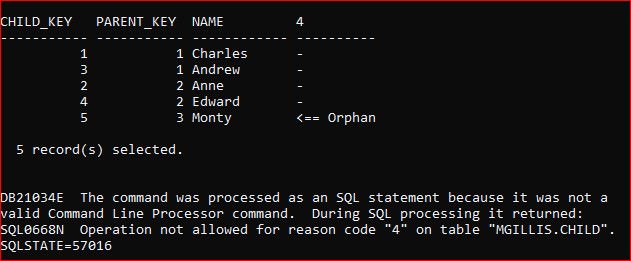
The error message tells you that this table is read-only and cannot be accessed for any update operation.
Even if you set the FK back to ENFORCED, the changes to the operation of the key will prevent anything happening to this table:

NB: I’ve not highlighted the changes from the previous view as everything has changed, except for the Table Status remaining in Integrity Pending. This does mean that even SELECT will fail now.
The way to deal with this quickly is to run

And we can see the effect in the RI view

Table Status and Access Mode have both changed, indicating that the database is accessible again, but the one to concentrate on is the FK Status. By “Unchecked” it means that the data will not allow any violations going forward but whatever is in there now will be accepted.
A warning message will confirm what has happened:

Hence our orphan data persists but any attempt to introduce further orphan rows will fail:
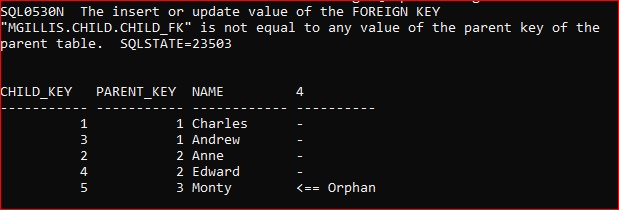
What we actually want to do is to put the table back into an accessible mode, with the FK operating and all data conforming to that FK.
So, we switch Integrity OFF again, and re-enable it with

The FK details show in the RI view as everything AOK

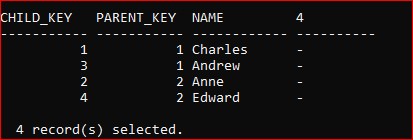
The orphan data is gone from the CHILD table
And the orphan row has now been moved to the nominated Exception table
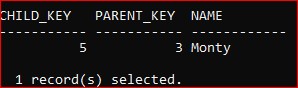
The downside of this process is that it can be very heavy-duty. If you have a large database with millions of rows and dozens of FKs then the process of checking all existing data for orphans can run for more than an acceptable period of outage for the application (remember the data might be in Read-Only access for the entire duration of the operation).
That’s probably enough for one session. In the next part we’ll look at the performance impact of FKs and how to manage that.
 About: Mark Gillis – Principal Consultant
About: Mark Gillis – Principal Consultant
Favourite topics – Performance Tuning, BLU acceleration, Flying, Martial Arts & Cooking
Mark, our kilt-wearing, karate-kicking DB2 expert has been in IT for 30+years (started very young!) and using DB2 for 20+. He has worked on multi-terabyte international data warehouses and single-user application databases, and most enterprise solutions in between.
During his career Mark has adopted roles outside of the conventional DBA spectrum; such as designing reporting suites for Public Sector users using ETL and BI tools to integrate DB2 and other RDMS data. He has worked extensively in the UK, but also in Europe and Australia, in diverse industry sectors such as Banking, Retail, Insurance, Petro-Chemicals, Public Sector and Airlines.
Currently the focus of Mark’s work is in Cloud migration and support, hybrid database enablement and providing expertise in exploiting the features and functions of Db2 V11.1 and 11.5.