

As we saw in the previous article, (DB2 for z/OS Locking for Application Developers Part 1) the ACID properties of database transactions (atomicity, consistency, isolation and durability) are intended to guarantee data integrity. It’s important to emphasize that data integrity is a joint responsibility of the DBMS and the application programmer, and that this is the primary focus of this series of articles – a database without integrity has little business and informational value. The DBMS provides the mechanisms – from the point of view of this series, locking – to guarantee data integrity, but it’s absolutely necessary for the application program to code correctly for the locking strategy used. However, the locking mechanism (or locking semantic) has an impact on transaction concurrency – it slows transactions down and makes it harder to run them alongside each other, because of lock contention and lock wait suspensions. These two issues are discussed in more detail in a later article.
For now, this article concentrates on the basic elements of DB2 for z/OS locking semantics. A solid understanding of how DB2 for z/OS locks database objects – tablespaces, tables, pages and rows – is needed to be able to understand the data integrity implications of striking a balance between transaction isolation and transaction concurrency.
Each DBMS uses its own locking semantics. Oracle locking semantics, for example, are very different from those used by DB2 for z/OS. The design point of standard1 DB2 locking semantics is to always present committed data and only committed data to the application (with the “dirty read” exception, which is discussed later in the series). That is, the data is always transactionally consistent. This means that if an in-flight transaction has updated some data, then other transactions that want to access that data have to wait until (i) the first transaction has told DB2 that it wants to make its changes permanent by issuing a commit and (ii) DB2 has released the locks. Alternatively, the first transaction could have told DB2 to roll back the changes if a problem has been encountered, which impacts concurrency even more as rolling back the changes extends the period of time the locks are held for, increasing lock contention.
Given this, an implication is that DB2 decides what to lock, when to lock it, and when to release the lock. This is mostly true, with a few exceptions such as SQL DML statements like LOCK TABLE IN SHARE MODE, which we’ll come across later in this series. However, some aspects of DB2’s locking strategy are controlled by BIND options and we’ll see in this series how those bind options affect the way application programs should be coded to guarantee data integrity.
This brings us onto a key part of DB2 locking semantics – lock size (including hierarchical locking). This combines with another important concept introduced in this article, lock mode, to help the application programmer or designer manage the balance between transaction isolation and transaction concurrency.
DB2 allows you to choose whether to lock at the tablespace, table, page or row level by specifying the LOCKSIZE attribute on the CREATE or ALTER TABLESPACE DDL statement. As of DB2 12, with simple, segmented and classic partitioned tablespaces deprecated at function level 504, tablespace and table locks effectively become UTS partition locks, as illustrated in the green box in Figure 1. Throughout the following discussion, for “tablespace” read “tablespace or partition” unless otherwise explicitly stated.
DB2 uses a mechanism called hierarchical locking (see Figure 1), to optimize transaction concurrency, with tablespace/partition at the top of the hierarchy and page/row at the bottom. A lock is always acquired at the top of the hierarchy, without exception. If you specify LOCKSIZE TABLESPACE or TABLE2, locks are only obtained at the top of the hierarchy. Locks are obtained at the bottom level in the hierarchy only if you specify LOCKSIZE PAGE or LOCKSIZE ROW (or LOCKSIZE ANY, which in most cases results in LOCKSIZE PAGE).
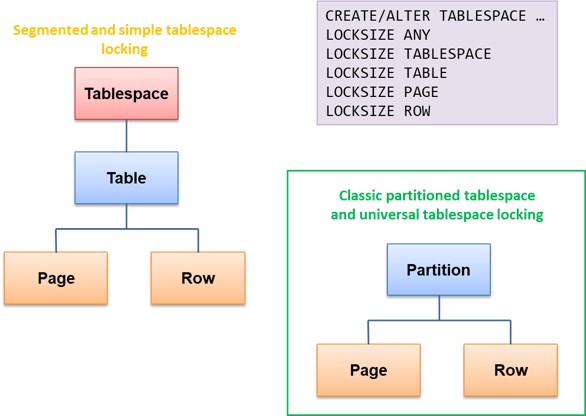
Figure 1 DB2 Hierarchical Locking
Tablespace locks for LOCKSIZE TABLESPACE are known as gross locks, because the application is taking a share or exclusive lock on the entire object. If you specify LOCKSIZE PAGE or ROW, you only get share and exclusive locks on the page or row, but you also get locks on the tablespace known as intent locks. You can also get gross locks even with LOCKSIZE PAGE/ROW by coding EXEC SQL LOCK TABLE IN SHARE/EXCLUSIVE MODE.
What’s the difference between a gross lock and an intent lock? To expand on the definition of a gross lock as a lock on the entire object (tablespace, partition or table), it’s a way of applying that lock to every single page and row in the tablespace in one go without the CPU or elapsed time cost of acquiring all those locks. Gross locks can be useful for performance reasons in a number of circumstances:
- If you know that the tablespace is read-only and is never updated when it is being read. For example, if a reference table only needs to be updated once a day, replacing the contents of the tablespace using the LOAD utility is possible if the daily schedule shuts the read-only application down long enough to allow the table to be updated.
- If you know that an application program is the only one accessing the table, then it’s safe to take an exclusive lock preventing any other user from accessing while the program is running.
- I’ve heard this suggested but never seen it in practice: using the tablespace as an application serialization point. This is very difficult to achieve and at the same time maintain performance, as the serialization point will very quickly become a bottleneck.
In all these cases, If the number of pages/rows accessed is small, it might be difficult to measure the CPU and elapsed time savings. On the other hand, if the number is large, the benefits can be very significant. While applications accessing that tablespace will run more quickly and cheaply than if they acquired page or row locks, there is a significant impact on concurrency. Share-mode gross locks prevent any concurrent transactions from updating the table, and exclusive-mode gross locks prevent any other concurrent transactions from accessing the table at all. Be aware that gross locks are held until the transaction commits or terminates3.
An intent lock is very different. It signals your intention to read or update a tablespace concurrently with other transactions. As well as reading the tablespace, these other transactions might also be updating it at the same time as you are (reading or updating it). This is dependent on them having also taken intent locks4. Intent locks are essential if there is concurrent access to a tablespace involving updates as well as reads. The most common form of tablespace lock is the intent lock rather than the gross lock, because of the need for concurrency. Consequently, most tablespaces are defined with LOCKSIZE PAGE or ROW. There is an option to specify LOCKSIZE ANY, and although this nearly always resolves to LOCKSIZE PAGE, it is recommended that you explicitly specify the lock size, if only for documentation purposes.
Locks on pages and rows are not categorized as gross or intent locks, partly because there are no intent locks at the page or row level, and partly because the whole object is not being locked. They are just classified as … well, page locks and row locks.
Now we’ve discussed hierarchical locking and lock size, and described the difference between gross locks and intent locks, I can introduce lock modes. Different lock modes are acquired depending on whether the database object (tablespace, page or row) is being updated or read. A lock for read is a share lock, whereas a lock for update is an exclusive lock. In DB2 for z/OS, these are referred to as S and X locks respectively. An S lock allows concurrent readers but no concurrent updaters, whereas an X lock allows no concurrency at all.
Having introduced them, in the next article I go into more detail about the various lock modes, at tablespace level and at page/row level, including the update or U lock, and discuss incompatible locks and what happens when these are encountered.
If you need help with Data Integrity, talk to us.
Footnotes
1 The BIND option that affects this, RELEASE(COMMIT|DEALLOCATE) is discussed in a later article in the series.
2 This is with the exception of the esoteric SIX lock, which is a sort of hybrid gross/intent lock. The SIX lock is described in the next article.
3 I say “standard” because DB2 10 introduced partial support for another locking semantic called Currently Committed which was intended to make porting applications from other database managers easier. However, the Currently Committed semantic was never fully implemented and is not discussed here (in fact, I don’t know anyone who uses it).
4 According to the DB2 SQL Reference, you should specify LOCKSIZE TABLE only for a segmented (non-UTS) table space. In practice, it only makes sense to specify this for a multi-table segmented tablespace, bearing in mind that these are deprecated as of DB2 12 function level 504.
Db2 for z/OS-locking for Application Developers eBook
Gareth's eBook focuses on the role of the application programmer in collaborating with the locking mechanisms provided by Db2 to ensure data integrity.