

The previous blog (Behind the scenes with Foreign Keys part 1) was looking at the impact on your data of switching Foreign Keys (FKs) off and how to clean up the ensuing orphan data. I’m going to move on now to what can happen to your access paths regardless of any data manipulation.
Performance Impact
There are ways of influencing how much performance impact an FK can have on your database. One theory of relational database design suggests that the FKs are enabled only in the non-Production environments. Once the data flow is tested and total confidence in the design has been established, they can be dispensed with or, at least, disabled to obviate the performance impact that continually exercising them might have.
Care must be taken, however, as this can have a negative effect on performance too.
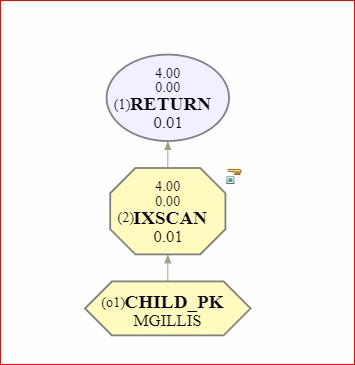
If we run this simple query in Explain mode, for instance, with everything set “on”, as in our last look at the RI view

we get a very good Estimated Cost and an access path that uses the Primary Key on the CHILD table in a simple Index Only Scan
However, if you disable the FK you can provoke the optimizer into choosing a sub-optimal access path. You switch off the FK for optimization by using

and the access path becomes
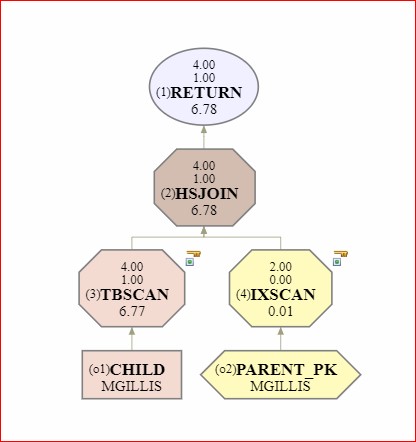
Clearly not a big problem when the CHILD table only has 4 rows, but you can see how this will pan out if it has 4 million rows, or 40 million…
But the FK is still enforced, even if it is disabled for Query Optimization

and will prevent any orphan data being created

But what happens if you reverse those parameters? You can enable the FK for Query Optimization but have the FK not enforced and not trusted:

What you get is the same sub-optimal access path
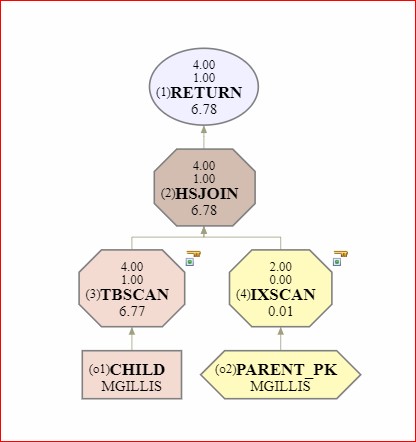
This is because (to quote directly from the manual)
“If a constraint is NOT TRUSTED and enabled for query optimization, then it will not be used to perform optimizations that depend on the data conforming completely to the constraint”
But if you leave Query Optimization enabled, leave the FK not enforced but switch the Trusted option back on:

You return to the best access path:
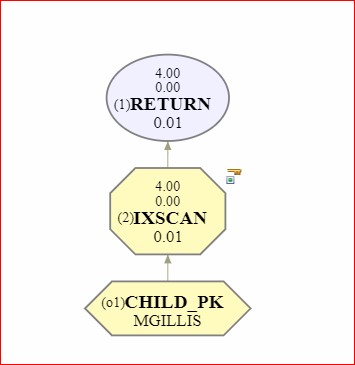
BUT you can introduce orphan data.
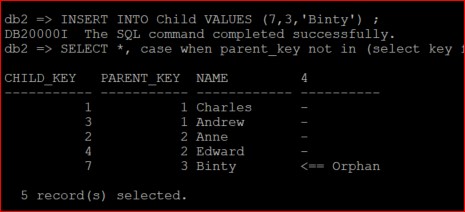
So, this last option is the one you would use to enable optimum query performance as long as you trust that your application cannot create orphan data and you don’t want the performance overhead of continually exercising the processing that the FKs will invoke.
Conclusion
FKs are often used as a relatively blunt tool in the exercise of Relational Design but there are degrees of subtlety in there. A fairly common performance issue for us when Triton take on a new customer and give their database a health check is to see FKs in place but unchecked, carrying an overhead of large quantities of orphan data or being unnecessarily executed in a system that doesn’t need the expensive data scrutiny. Hopefully these blogs will give you a few pointers for how to use FKs in the most optimal fashion for your database.
The queries and commands referred to in this blog can be downloaded from the BitBucket below:
This is a single script that can be run against any existing database. It will create test objects, execute the tests and “clean-up” afterwards. If run from a Windows CLP you can leave the pause commands in; if you’re running from a Unix environment, you’ll want to comment those out and uncomment the read comments (assuming you want the script execution to halt at the specified points so you can read the output).
I’d recommend running this as db2 -tf Referential_Integrity_enabled.sql to avoid the execution stopping completely when you hit an error, of which there are several deliberately built in.
I’m also have a version of this as a Jupyter Notebook (and my sincere thanks to Ember Crooks for her assistance with this), so please drop me a line if you’d be interested in a copy, or if you have any questions or comments.
E-mail: Mark.Gillis@triton.co.uk
Mobile: +44 (0)7786 624704
 About: Mark Gillis – Principal Consultant
About: Mark Gillis – Principal Consultant
Favourite topics – Performance Tuning, BLU acceleration, Flying, Martial Arts & Cooking
Mark, our kilt-wearing, karate-kicking DB2 expert has been in IT for 30+years (started very young!) and using DB2 for 20+. He has worked on multi-terabyte international data warehouses and single-user application databases, and most enterprise solutions in between.
During his career Mark has adopted roles outside of the conventional DBA spectrum; such as designing reporting suites for Public Sector users using ETL and BI tools to integrate DB2 and other RDMS data. He has worked extensively in the UK, but also in Europe and Australia, in diverse industry sectors such as Banking, Retail, Insurance, Petro-Chemicals, Public Sector and Airlines.
Currently the focus of Mark’s work is in Cloud migration and support, hybrid database enablement and providing expertise in exploiting the features and functions of Db2 V11.1 and 11.5.