

In Part 1 I showed how to setup a simple TSA/HADR cluster consisting of two servers, and what happens to an active client connection in case of a failover.
In Part 2 and Part 3 we saw how ACR and VIP independently affect a client’s connection in case of a failover in the cluster.
In this final part, we will once again reconfigure the TSA/HADR cluster, this time to use VIP and ACR together and check their combined effect on the client processing during and after a failover.
TSA/HADR failover with ACR+VIP
With VIP already set up in Part 3, what remains is to configure ACR.
Only, this time we will use the VIP address for the alternate server specification, rather than the real TCP/IP addresses of servers Itchy and Scratchy:
Primary (ITCHY, 192.168.20.64):

Standby (SCRATCHY, 192.168.20.65):

The fresh client’s connection to the SAMPLE database proves the VIP and ACR settings are in place:
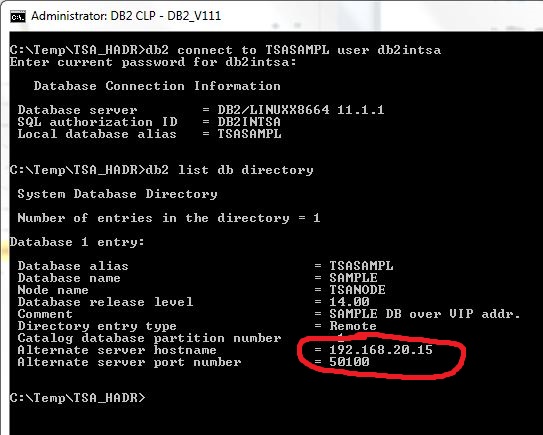
Executing the failover:
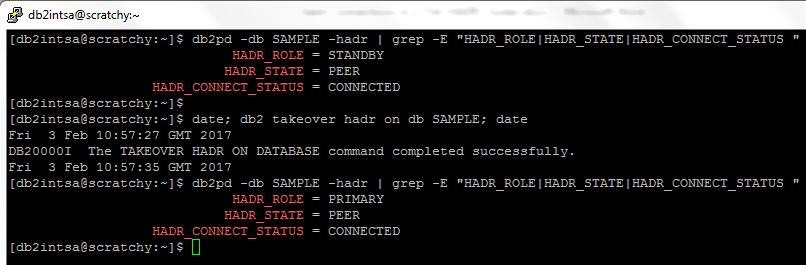
And this is what happened on the client this time:
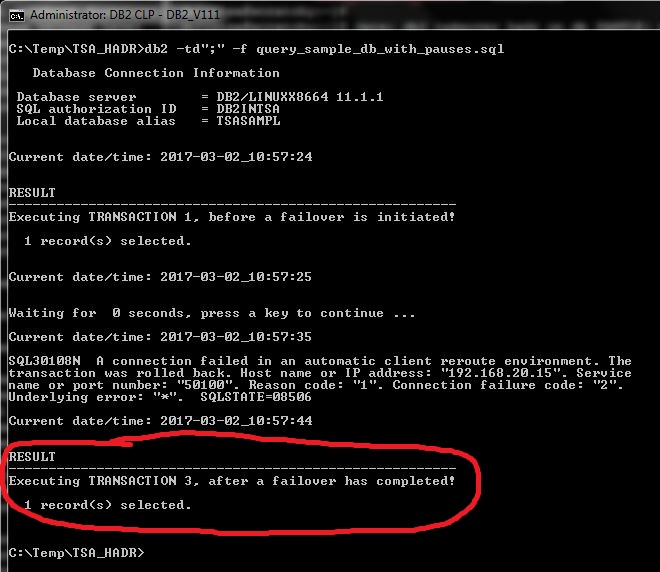
We can see that the “in-flight” transaction failed again as expected, but the next transaction executed successfully, meaning that the client has automatically recovered its database connection following a failover and continued its batch job processing, with no need for any user intervention!
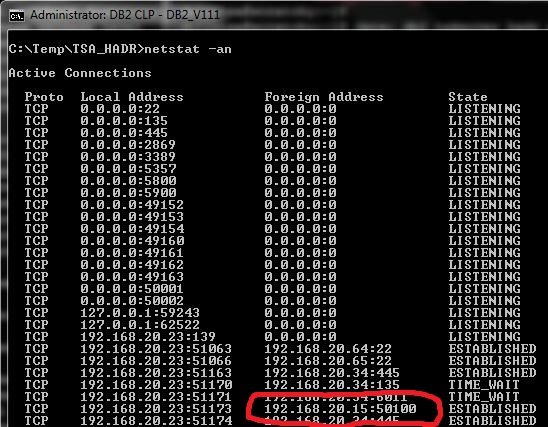
The client is still connected to the database on the same TCP/IP address, the VIP address:
Conclusion
Using the VIP address and the ACR setting together in a TSA/HADR cluster enabled the client to automatically recover from a database failover with minimum damage – only the in-flight transaction was rolled back – and to continue its batch job processing as if nothing happened.
When the DBAs arrive at work next day, they might notice that the failover happened (but only if they look in the DB2 logs, or at the results of a batch process that was active during the failover).
On the other side – the AppDev team, test team and/or end users will never know that anything happened at all. Unless the DBA tells them J
Of course, care should be taken to reexecute all failed transactions where necessary, that is – where the client itself has not done that automatically.
What more could a DBA want?