

This is the sixth article in the series on DB2 for z/OS Locking for Application Developers. The primary focus of this series is to help DB2 for z/OS application developers to guarantee data integrity while optimising for performance by designing and coding applications which take into account the following : the ACID properties of database transactions; lock size, lock mode and lock duration in DB2 for z/OS; compatible and incompatible locks; and how DB2 isolation levels provide application-level controls to establish the balance between (i) the degree of transaction isolation required to guarantee data integrity and (ii) the need for concurrency and performance.
In this article, I’m going to move on to look at some of the data anomalies that applications are exposed to and which isolation levels are susceptible to those data anomalies. I’ll then discuss two factors which complicate the task of managing the effect of DB2 locking semantics on data integrity: ambiguous cursors; and the CURRENTDATA option for BIND.
 Without transaction isolation, applications can encounter a variety of data anomalies:
Without transaction isolation, applications can encounter a variety of data anomalies:
- The phantom row or phantom read anomaly
- The non-repeatable read anomaly
- The dirty read anomaly
- The lost update anomaly
I’ll go through these in turn, and then in the next article discuss which isolation levels are susceptible to each anomaly.
Phantom row or phantom read anomaly
The standard definition of this is that during the course of a transaction which accesses the same set of rows twice, new rows are added to the result set. This can be illustrated by a simple diagram:
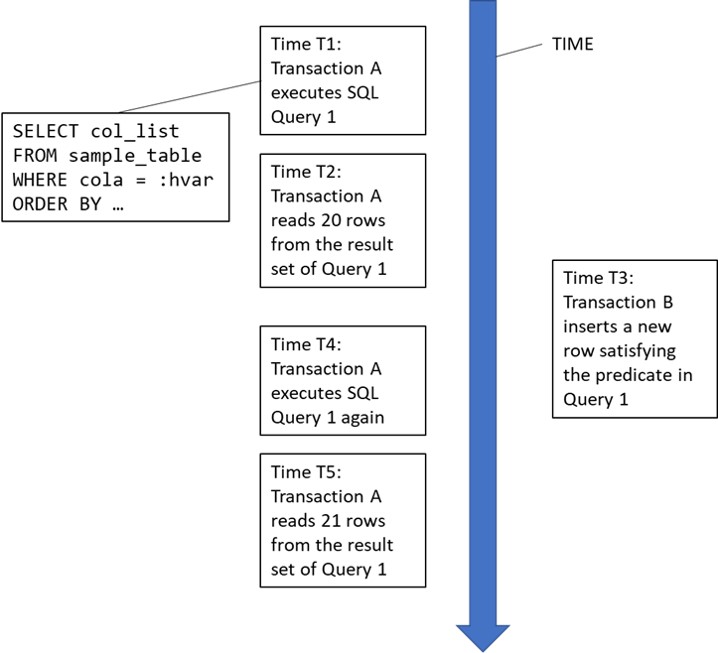
It’s possible to construct a number of use cases where a transaction might be susceptible to the phantom read anomaly. For example:
Phantom Read Example 1: A complex analytical transaction reads a large number of rows from a table several times for joining with multiple other data sets, including other tables and data sources external to the database manager. Some joins are performed programmatically by the application, others are performed by DB2 itself. Because of the large number of rows involved, the transaction cannot store them all in its working storage area. However, if additional rows appear in the result set from one execution to another, the analysis is invalidated.
Phantom Read Example 2: This example might be considered controversial, because it involves update operations as well as read operations.
A transaction T1 reads rows from a table using one or more predicates, the predicate set P1. It programmatically evaluates the result set, and makes a decision whether or not to proceed with a searched update of the entire result set, again using the predicate set P1. If the result set changes with new rows appearing in the result set because of INSERT or UPDATE operations performed by other transactions between the SELECT and UPDATE operations performed by transaction T1, then although the ‘phantom’ row is not seen directly by transaction T1, the premise on which the decision to update the result set is invalidated, and the phantom rows are updated as well as the rows previously read.
Non-repeatable read anomaly
With the non-repeatable read anomaly, a row is accessed more than once during the course of a transaction and the row values change between accesses:
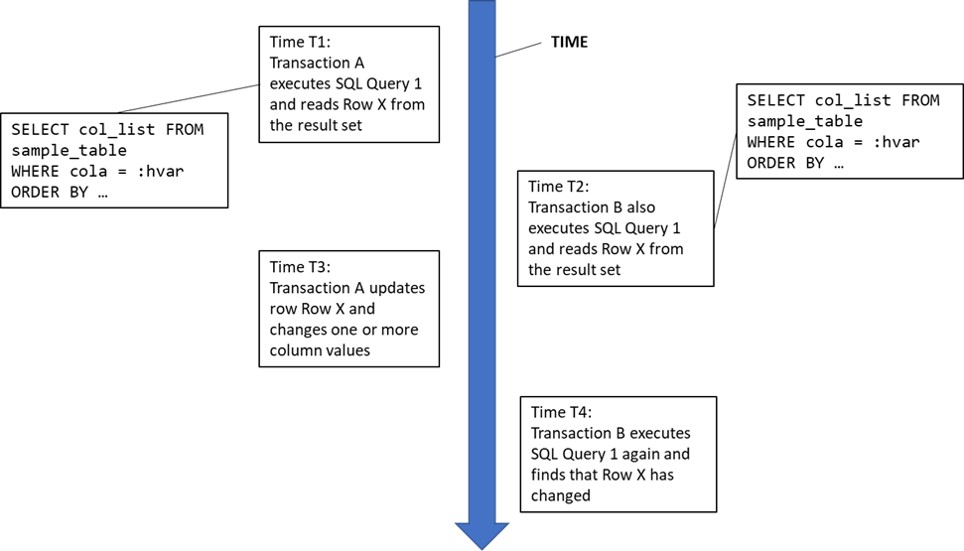
Again, there is a number of use cases where the non-repeatable read anomaly could be encountered, but only one example is presented:
Non-repeatable Read Example: This example is startlingly like phantom read example 1, but the apparently minor difference is the key point that distinguishes these two anomalies. A complex analytical transaction reads a large number of rows from a table multiple times for joining with multiple other data sets, which could be other tables or other data sources external to the database manager. The join could be performed programmatically by the application, or it could be performed by the DBMS itself. Because of the large number of rows involved, the transaction cannot store them all in its working storage area. However, if any changed rows appear in the result set or rows from the result set are deleted between executions, the analysis is potentially invalidated.
Dirty read anomaly
The dirty read anomaly is where a transaction reads changed data before it was committed. For a data integrity exposure to occur, the update transaction must be rolled back, and the transaction that read the uncommitted update must commit:
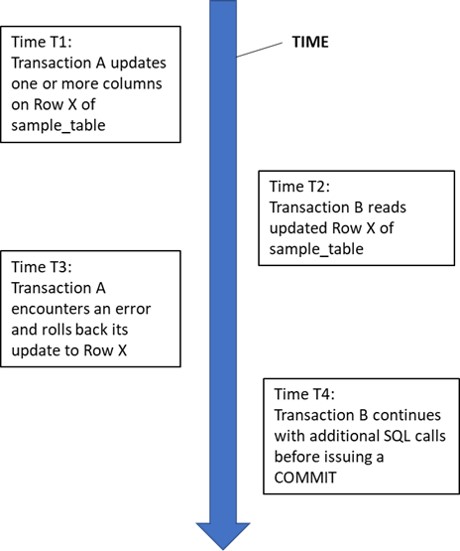
Dirty Read Anomaly Example 1: A bank account transaction reads rows without being aware if the rows it sees contain committed data or have been updated by another transaction which has not yet committed. It returns the information retrieved back to the end user. If one or more of the rows read contained uncommitted updates from another transaction which is subsequently rolled back (the updates are undone by the DBMS), then incorrect information is reported back to the end user.
Dirty Read Anomaly Example 2: A bank account update transaction reads rows without being aware whether the rows it sees contain committed data or have been updated by another transaction which has not yet committed. It uses the retrieved data to update other banking information, either in the same table or one or more other tables. If any of the data used to drive updates was read from a row containing uncommitted updates from another transaction which is subsequently rolled back, undoing the updates, then data corruption is possible if not probable.
Lost update anomaly
The lost update anomaly is perhaps the most obvious anomaly leading to data corruption and occurs when two transactions both read and update the same row, but the second transaction overwrites the first transaction’s update:

The above diagram doesn’t really need an example to illustrate that data corruption occurs with the lost update anomaly, other than to say that when transaction B commits Col Y of Row X should have a value of 20, not 10 (the original value of 5 incremented by 10 and then incremented by a further 5, i.e. 5 + 10 = 15, 15 + 5 = 20).
The next article will start off by listing which transaction isolation levels are vulnerable to each data anomaly, and then moves on to discuss data integrity complications arising out of the use of cursors to read data, including the topic of data currency, and the DB2 bind option, CURRENTDATA, which is intended to provide optimal performance but introduces additional considerations for data currency and data integrity.
Struggling with Db2 Locking?
We’ve helped countless teams overcome Db2 locking challenges. Yours could be next. Contact us.
Db2 for z/OS-locking for Application Developers eBook
Gareth's eBook focuses on the role of the application programmer in collaborating with the locking mechanisms provided by Db2 to ensure data integrity.