

Introduction
The main purpose of setting up a Db2 HADR cluster – just as its name implies – is to provide a level of High Availability and Disaster Recovery for the contained Db2 database (or databases). In other words, HADR will make our databases more resilient.
To handle the High Availability aspect, we will typically set up a cluster consisting of just two nodes and configure them for Db2 HADR. These nodes – called the primary and the main standby – will typically be members of the same network subnet and (preferably) geographically close to each other. For example, they will reside within the same on-prem data centre or within the same Region/Availability Zone of the (same) Cloud provider. This is to ensure that the failover to the other node can be done as swiftly as possible, in a case where the primary node fails. We can make this even better and configure Pacemaker to automate the failovers on both nodes (but I will not discuss Pacemaker here, please read my other articles if you want to get more details about that technology: Automating HADR Failovers with Pacemaker, Configuring Db2 Pacemaker HADR cluster with QDevice in AWS and Db2 Pacemaker HADR Seamless Failover).
To take care of the Disaster Recovery requirements, we will typically add additional nodes to the HADR cluster: one or more Auxiliary Standbys (max two with the current Db2 releases). In contrast to the two “main” nodes (the primary and the main standby), these AUX Standby nodes should be physically distant from the rest of the cluster. For example, they will be placed in a different data centre, tens of kilometers away, on a different tectonic plate… or in a different region of the (same) Cloud provider… This will ensure a copy of the database survives a catastrophical event where the whole main data centre (or a cloud region) is destroyed. But even so, these remote nodes must remain on the same network (if not subnet) in order to be able to communicate with each other.
But what if we want to go another step further and set up a HADR cluster with its nodes spread across different Cloud providers (or Data Centres), with the goal of providing additional levels of Disaster Recovery for our databases?
How will that work?
Will that work?
Let’s find out!
NOTE: in the rest of this article, I will only discuss the hybrid configurations spanning different cloud providers (namely: AWS and Azure; the only testing playground available to me at the time), but the concepts should be the same for the on-prem data centres, any other cloud providers, and/or any combination of the two.
The Hybrid Problem
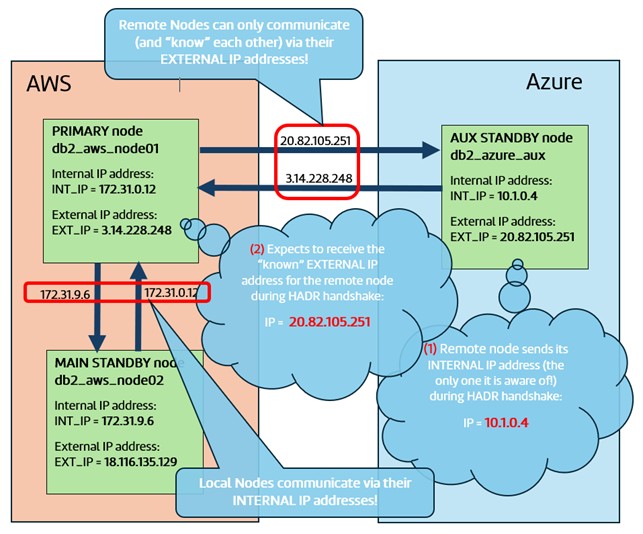
The main problem with the Hybrid approach is that there will almost inevitably be a NAT Firewall (or Gateway?) somewhere between the remote nodes.
NAT Firewall is used to translate the local node’s internal IP address (reachable only within the local network) into an external IP address (reachable worldwide), and vice versa. This will allow the remote nodes to communicate and “see” each other by using the other node’s external IP address, even though the nodes themselves are not aware of having these external IP address at all.
And that exactly is the problem:
When a HADR cluster is started, all configured nodes will initiate a handshake amongst themselves where they will try to match the other node(s) IP addresses against their local HADR configuration. Each node will advertise itself by using its internal IP address (because that is the only IP address it is aware of). And this will inevitably fail on any remote node (sitting behind a NAT Firewall) which only knows the other node’s external IP address (written in its HADR configuration).
Below is the diagram of a Hybrid HADR test cluster, consisting of two AWS nodes and one Azure node, that I had set up a while ago to demonstrate the problem:
When I tried to start HADR in this cluster, it failed for the reasons explained above, all confirmed by the messages in the Db2 diagnostic log:
Db2DIAG.LOG on the Primary node (db2_aws_node01):
2024-08-16-08.46.14.718108+000 I4687004E524 LEVEL: Info
HADR_LOCAL_HOST db2_aws_node01, HADR_LOCAL_SVC 50100 is resolved to 172.31.0.12:50100
Remote end db2_azure_aux:50100 (based on HADR_TARGET_LIST) is resolved to 20.82.105.251:50100
Remote end db2_aws_node02:50100 (based on HADR_TARGET_LIST) is resolved to 172.31.9.6:50100
MESSAGE : Primary Started.
2024-08-16-08.46.27.884381+000 I4709946E747 LEVEL: Error
FUNCTION: Db2 UDB, High Availability Disaster Recovery, hdrVerifyIPAddrs, probe:100
DATA #1 : <preformatted>
Unable to verify the remote host information in the handshake ack message.
Configured remote host IP Address: 20.82.105.251.
Configured remote host port: 50100.
Remote host IP Address in handshake ack message: 10.1.0.4.
Remote host port in handshake ack message: 50100.
2024-08-16-08.46.27.884448+000 E4710694E758 LEVEL: Error
FUNCTION: Db2 UDB, High Availability Disaster Recovery, hdrHandleHsAck, probe:30420
MESSAGE : ZRC=0x87800140=-2021654208=HDR_ZRC_CONFIGURATION_ERROR
"One or both databases of the HADR pair is configured incorrectly"
DATA #1 : <preformatted>
HADR_LOCAL_HOST:HADR_LOCAL_SVC (db2_azure_aux:50100 (10.1.0.4:50100)) on remote database is not included in HADR_TARGET_LIST db2_aws_node02:50100|db2_azure_aux:50100 on local database.
2024-08-16-08.46.27.884555+000 E4711453E578 LEVEL: Error
MESSAGE : ADM12513E Unable to establish HADR primary-standby connection because the primary and standby databases are incompatible. Reason code: "4"
2024-08-16-08.46.27.884849+000 I4712032E676 LEVEL: Warning
A rejection message sent to HADR_LOCAL_HOST:HADR_LOCAL_SVC is db2_azure_aux:50100 (10.1.0.4:50100
2024-08-16-08.46.35.203521+000 I4713118E568 LEVEL: Error
The HADR primary was not able to form a TCP connection with the standby: 20.82.105.251:50100.
2024-08-16-08.46.35.203698+000 E4713687E540 LEVEL: Error
MESSAGE : ADM12510E Unable to establish HADR primary-standby connection with host:
"hadr_target_list.". Reason code: "10"
Db2DIAG.LOG on the AUX Standby (db2_azure_aux):
2024-08-16-08.46.27.919925+000 I50141E495 LEVEL: Info
Handshake HDR_MSG_HDRREJECT message is received from db2_aws_node01:50100 (172.31.0.12:50100
2024-08-16-08.46.27.949846+000 E50637E531 LEVEL: Error
MESSAGE : ADM12519E This HADR standby database has been rejected by the HADR primary database
DATA #1 : ZRC, PD_TYPE_ZRC, 4 bytes
0x87800140
2024-08-16-08.46.27.950052+000 I51169E613 LEVEL: Error
MESSAGE : ZRC=0x87800140=-2021654208=HDR_ZRC_CONFIGURATION_ERROR
"One or both databases of the HADR pair is configured incorrectly"
DATA #1 : <preformatted>
HADR handshake with db2_aws_node01:50100 (172.31.0.12:50100) failed.
So, with the problem (hopefully) explained, let’s look at the potential solutions.
The Solution (old one)
The “old” solution (as I like to call it) has been around for quite a while – since v9.7 at the least, and it uses a special registry variable: Db2_HADR_NO_IP_CHECK, which basically instructs the HADR nodes to skip the remote node IP address checking during the HADR handshake and just establish a connection
(a bit more details here: https://www.ibm.com/docs/en/db2/9.7?topic=support-hadr-nat ).
In theory, this is a very simple solution, and – when configured – this will appear in the Db2 diagnostic log to confirm the bypass is working as designed:
FUNCTION: DB2 UDB, High Availability Disaster Recovery, hdrHandleHsAck, probe:43900
DATA #1 : <preformatted>
Handshake HDR_MSG_HDRHS message is received from db2_aws_node02:50100 (172.31.9.6:50100)
...
FUNCTION: DB2 UDB, High Availability Disaster Recovery, hdrIsIPValid, probe:15550
DATA #1 : <preformatted>
HADR local/remote host IP cross check bypassed per registry variable DB2_HADR_NO_IP_CHECK
However, in practice, apart from the above, I kept receiving the following messages as well:
FUNCTION: DB2 UDB, High Availability Disaster Recovery, hdrHandleHsAck, probe:43900
DATA #1 : <preformatted>
Handshake HDR_MSG_HDRHS message is received from db2_azure_aux:50100 (10.1.0.4:50100)
...
FUNCTION: DB2 UDB, High Availability Disaster Recovery, hdrVerifyIPAddrs, probe:100
DATA #1 : <preformatted>
Unable to verify the remote host information in the handshake ack message.
Configured remote host IP Address: 20.82.105.251.
Configured remote host port: 50100.
Remote host IP Address in handshake ack message: 10.1.0.4.
Remote host port in handshake ack message: 50100.
...
Obviously, this solution has some shortcomings (believe me, I double-checked, and triple-checked, the environment variable was properly configured on all HADR nodes involved!) and there doesn’t seem to be any other suggestions on how to fix these, except to use the “new method”, which “has a significant advantage over the old one”.
The “new method” is available from Db2 version 11.5.6.
The New Solution
The new method (or solution) relies on a new syntax for configuring the relevant HADR parameters (namely: HADR_LOCAL_HOST and HADR_LOCAL_SVC) in a NAT environment, where each HADR node may have two IP addresses assigned to it (and even operate on different ports internally and externally).
For example, using the same Test cluster as above, following is the list of the IP addresses and logical host names assigned to my two AWS nodes and one Azure node:
db2_aws_node01_int 172.31.0.12
db2_aws_node01_ext 3.14.228.248
db2_aws_node02_int 172.31.9.6
db2_aws_node02_ext 18.116.135.129
db2_azure_int 10.1.0.4
db2_azure_ext 20.82.105.251
Now, instead of configuring the local host parameter as:
db2 "update db cfg for SAMPLE using
HADR_LOCAL_HOST 'db2_aws_node01_int'"
We do it by concatenating both of its IP addresses (or logical names):
db2 "update db cfg for SAMPLE using
HADR_LOCAL_HOST 'db2_aws_node01_int|db2_aws_node01_ext'"
The same is done on all other nodes, on AWS Node02:
db2 "update db cfg for SAMPLE using
HADR_LOCAL_HOST 'db2_aws_node02_int|db2_aws_node02_ext'"
On Azure Node:
db2 "update db cfg for SAMPLE using
HADR_LOCAL_HOST 'db2_azure_int|db2_azure_ext'"
With such configuration in place, when the HADR nodes initiate the handshake, each one will advertise itself using both of its IP addresses, so the other nodes (those sitting behind a NAT Firewall or not!) will be able to match either one of them to their locally configured values.
For simplicity, during the testing, I configured all nodes in my Hybrid Test cluster to work on the same IP port (50100) internally and externally, so I didn’t have to alter the other parameter (HADR_LOCAL_SVC). Otherwise, I would have done it pretty much the same way as above, specifying both the internal and the external IP port to be used:
db2 "update db cfg for SAMPLE using
HADR_LOCAL_SVC '<int_IP_port>|<ext_IP_port>' "
For more information on this new method, please read the following document:
https://www.ibm.com/docs/en/db2/11.5?topic=support-hadr-nat
Test Results
So, how does this work in practice?
From my experience, it works. Fullstop 😊
When I configured the HADR parameters as shown above (more details below!), I was able to start my Hybrid Test HADR cluster without any issues (screenshots also below!).
One word of caution though: if you tried to use the environment variable Db2_HADR_NO_IP_CHECK ever before, make extra sure it is now unset on all HADR nodes. Otherwise, it will interfere with your cluster. It took me a few days (and cluster restarts) before I realised that it remained set on only one node, which was enough to cause trouble.
Following is the full configuration of my Hybrid Test cluster, for reference:
Hosts file
On each node, the internal and external IP addresses, together with the logical host names, are defined in the /etc/hosts file:
# DB2 HADR nodes, including internal and external IP addresses for all nodes:
#
10.1.0.4 db2_azure_aux_int
20.82.105.251 db2_azure_aux_ext
#
172.31.0.12 db2_aws_node01_int
3.14.228.248 db2_aws_node01_ext
#
172.31.9.6 db2_aws_node02_int
18.116.135.129 db2_aws_node02_ext
#
HADR Configuration
AWS_node01:
HADR local host name (HADR_LOCAL_HOST) = db2_aws_node01_int|db2_aws_node01_ext
HADR local service name (HADR_LOCAL_SVC) = 50100
HADR remote host name (HADR_REMOTE_HOST) = db2_aws_node02_int
HADR remote service name (HADR_REMOTE_SVC) = 50100
HADR rem. instance name (HADR_REMOTE_INST) = db2inst1
HADR target list (HADR_TARGET_LIST) = db2_aws_node02_int:50100|db2_azure_aux_ext:50100
HADR log write sync mode (HADR_SYNCMODE) = NEARSYNC
AWS_node02:
HADR local host name (HADR_LOCAL_HOST) = db2_aws_node02_int|db2_aws_node02_ext
HADR local service name (HADR_LOCAL_SVC) = 50100
HADR remote host name (HADR_REMOTE_HOST) = db2_aws_node01_int
HADR remote service name (HADR_REMOTE_SVC) = 50100
HADR rem. instance name (HADR_REMOTE_INST) = db2inst1
HADR target list (HADR_TARGET_LIST) = db2_aws_node01_int:50100|db2_azure_aux_ext:50100
HADR log write sync mode (HADR_SYNCMODE) = NEARSYNC
Azure_node:
HADR local host name (HADR_LOCAL_HOST) = db2_azure_aux_int|db2_azure_aux_ext
HADR local service name (HADR_LOCAL_SVC) = 50100
HADR remote host name (HADR_REMOTE_HOST) = db2_aws_node01_ext
HADR remote service name (HADR_REMOTE_SVC) = 50100
HADR rem. instance name (HADR_REMOTE_INST) = db2inst1
HADR target list (HADR_TARGET_LIST) = db2_aws_node01_ext:50100|db2_aws_node02_ext:50100
HADR log write sync mode (HADR_SYNCMODE) = NEARSYNC
If you read the above config carefully (and I don’t blame you if you didn’t 😊), then you must have noticed that the two AWS nodes are configured to communicate using their internal IP addresses. There is nothing wrong with that, as the two nodes are a part of the same network and that is certainly the preferred method for their communication. This doesn’t interfere at all with the (remote) Azure node getting in touch via their external addresses. Each pair of nodes can use either the internal or external addresses for their own communication, independently of the rest of the cluster.
With the above setup in place, I was able to start and stop my Test cluster as required, as well as failover (and failback) to each node in the cluster, including the (remote) Azure node:
Start HADR Cluster
Starting the HADR cluster with the AWS Node02 as the current primary:
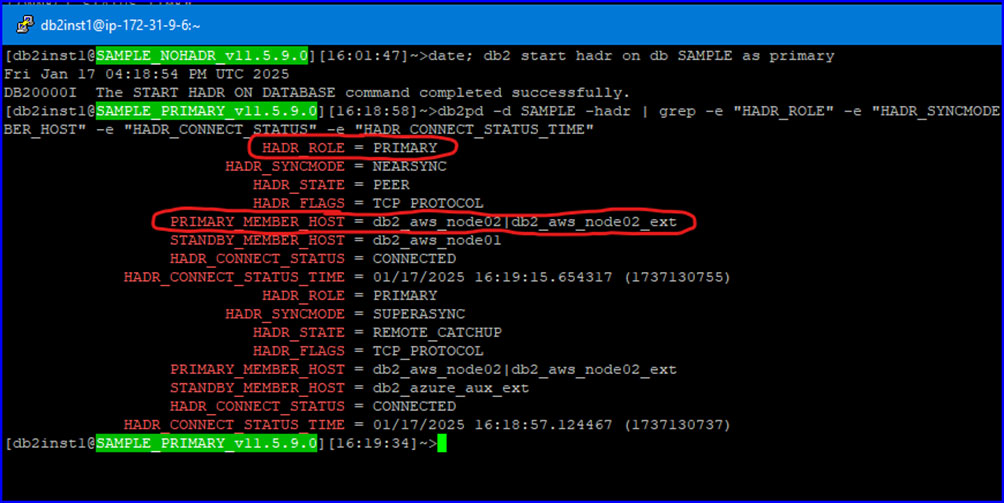
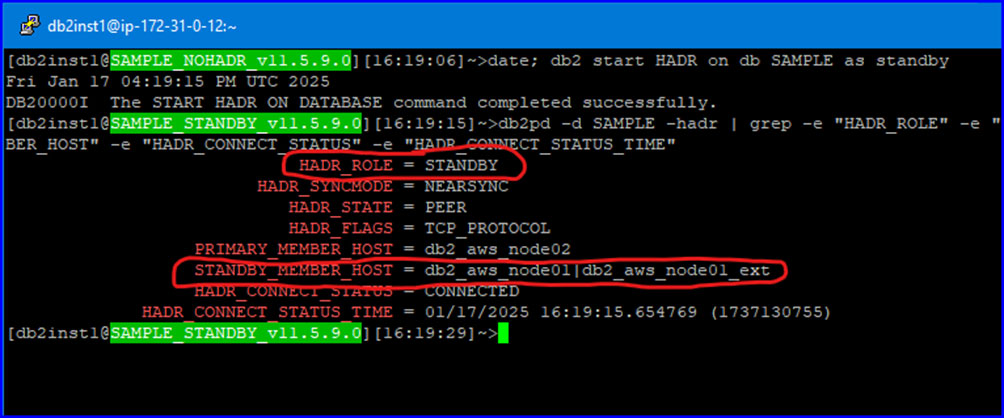
AWS Node01, current main standby:
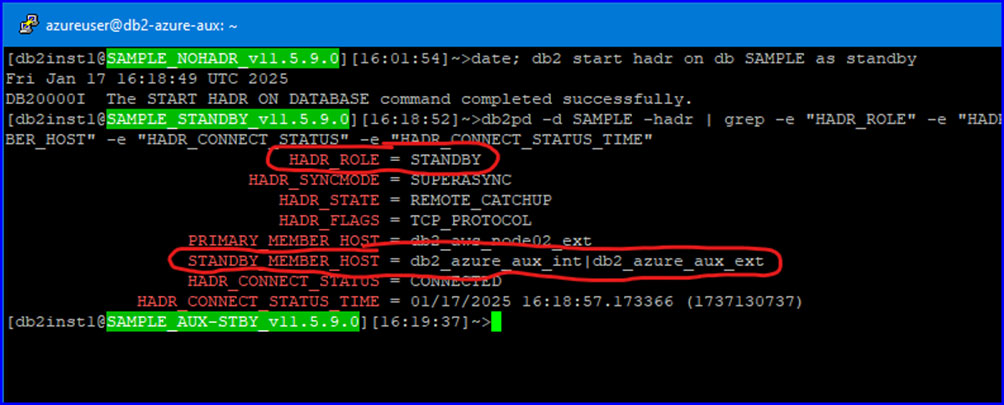
Azure Node, current AUX standby:
Failovers
Executing a failover to AWS Node01, with db2pd statuses shown both before and after the failover:
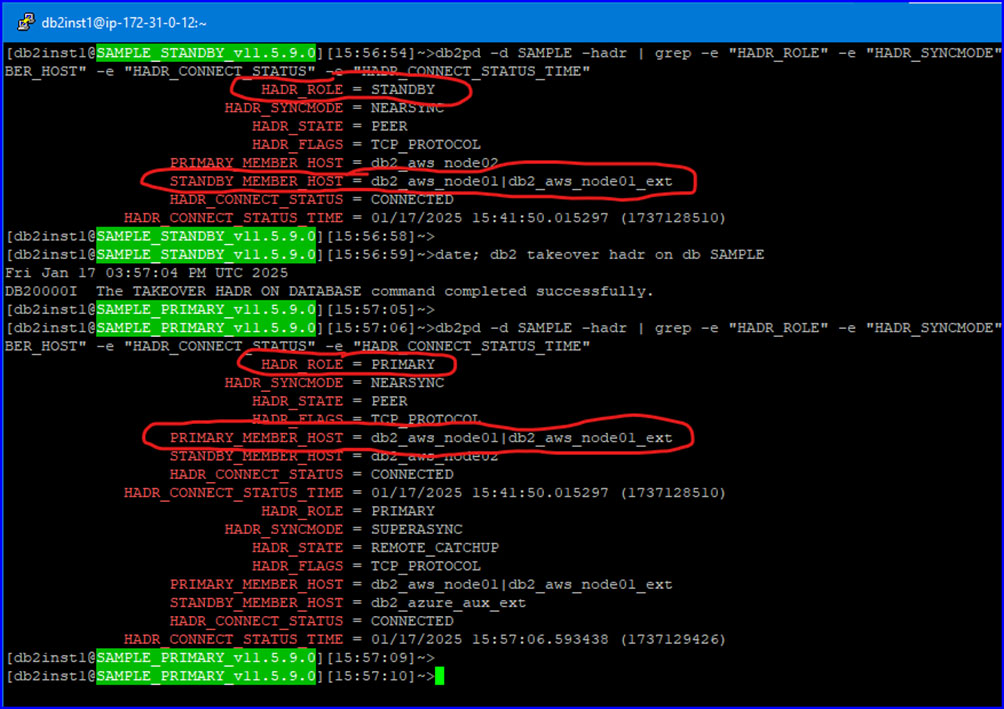
Failover to AWS Node02:
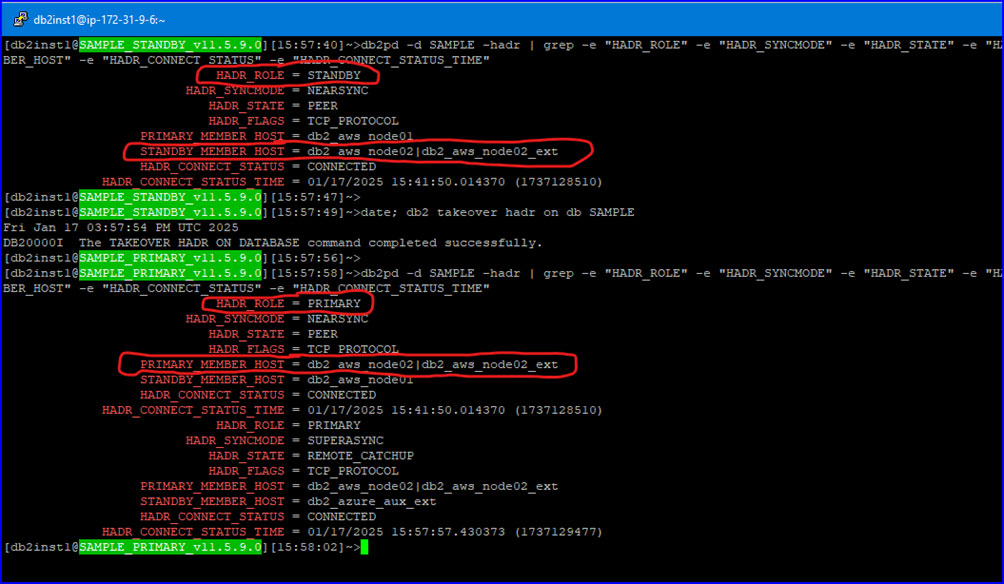
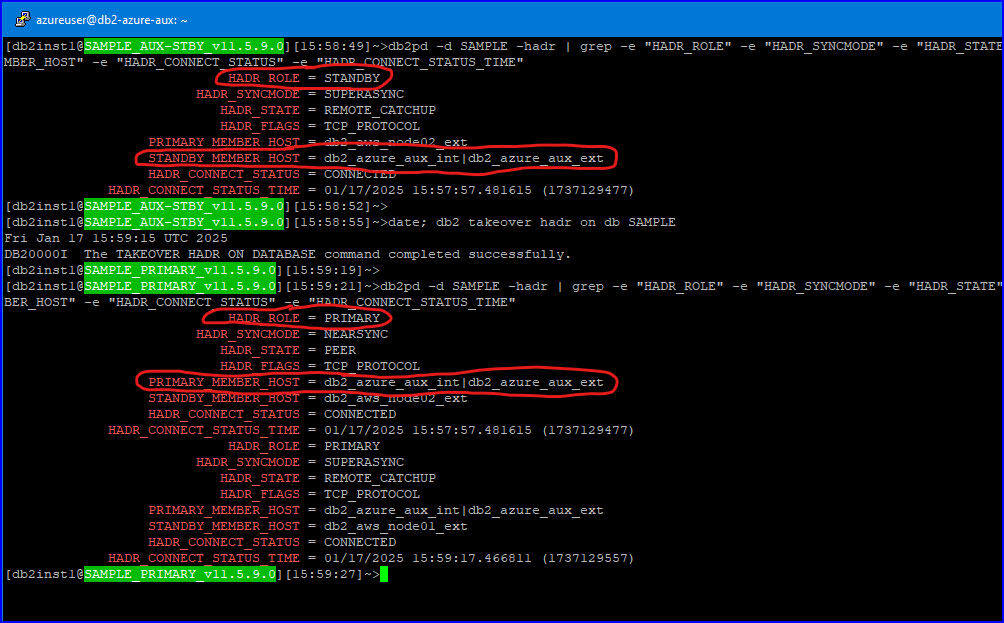
Failover to Azure Node:
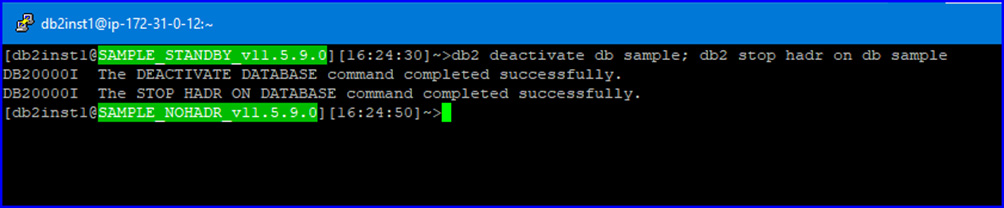
Stop HADR Cluster
Before stopping the cluster, I performed one more failover to (again) make the AWS Node02 the primary server, so that node gets a slightly different HADR shutdown procedure right now:
AWS Node01:
AWS Node02:
Azure Node:

Fun Fact #1: In the above testing, both AWS nodes were located in the us-east-2 (Ohio) Region, while the Azure node lived across the ocean – in the West Europe (Zone 2) Location. During the failover testing, when the Azure node became the primary, the main standby node (either one of the AWS nodes) remained in the NEARSYNC mode, very much according to the cluster configuration! This is clearly visible in one of the screenshots above. It would certainly be interesting to find out how this works under pressure, given the remoteness of the nodes, but I will leave that for another blog post.
Hybrid times, welcome!
To Be Continued…
In the second part of this blog series, we will extend our Hybrid cluster to include the GCP as well and will spread our test HADR nodes across all three major cloud providers: AWS, Azure and GCP!
Time (and resources) allowing, we will throw one on-premises node into the mix as well.
Stay tuned!