

Some time ago (over 4 years; where did that go?) I wrote a blog post about locating relevant data in tablespaces (tablespaces-where-exactly-is-my-data ). This continues that theme to an extent but has come about by trying to rationalise and ‘tidy-up’ a customer’s tablespace usage.
There are a few reasons you might want to do this:
- Table data can end up in Tablespaces designed for Indexes and vice-versa
- Tablespaces can still occupy space even if they’re ostensibly empty and will definitely do so if they only contain one or two objects
- Backup operations can parallelise by Tablespace but (unless you’re already on v12.1 and using Intra Tablespace Parallelism ) the backup will take as long as the largest tablespace. If one tablespace is ‘bloated’ with objects, that’ll be your bottleneck
The exercise I wanted to conduct was to
- move tables (data) out of Index Tablespaces (and vice-versa)
- identify and remove any empty tablespaces (and to empty out ones that only contain one or two objects)
- try and move objects around so that the tablespaces were a little more consistent in size
“Misplaced” objects
I referred to this issue in the previous blog: basically it comes down to the fact that, if you don’t specify a tablespace, Db2 will try and find an appropriate one for you.
Here is the reference again (CREATE TABLE statement ) but the bottom line is
“If more than one table space still qualifies, the final choice is made by the database manager”
Consequently, tables and indexes can end up in tablespaces that were originally defined for something quite specific and not appropriate for generalised or default usage.
For instance, you might have a group of tables and their associated indexes and you know that they are frequently and continually referenced. You’d like to keep as much of this data (and I include index information in that definition in this example) in memory as possible. Hopefully, your indexes occupy a smaller footprint than the underlying data and, as you’ve done a lot of tuning to allow transactions to make use of Index and Index-Only scanning, you have a smaller tablespace for the indexes, with a dedicated BufferPool, allowing the Index references to persist in memory and be accessed as quickly as possible.
And then someone comes along and puts a huge table into your Index Tablespace. It won’t be catastrophic but it sure as hell isn’t going to help performance. And that action of putting this table into the Index Tablespace doesn’t have to be deliberate; if you didn’t specify a tablespace, Db2 might just decide that that is the best fit.
Empty tablespaces that aren’t
Another case that we have is tablespaces that should no longer be in use but are still persisting due to ‘something’ having been placed in there. Where this shows up most often is with our Partitioned Tables Housekeeping. We have customers who typically keep x months of data and rely on us to supply new partitions as needed, and to archive off the oldest ones, for performance. So, typically, we would
- create a couple of new tablespaces; one for data and one for indexes, and give them a name that clearly shows their intended function e.g. tablename_DATA_202503 and tablename_INDEX_202503
- create a new Partition with
ALTER TABLE tablename ADD PARTITION tablename_202503
(starting and ending criteria)
IN tablename_DATA_202503
INDEX IN tablename_INDEX_202503
Then we have the flip-side of the operation where we detach the oldest partition. Having found the partition that is x + 1 month old, we
• deal with any Foreign Key constraints (see https://www.triton.co.uk/behind-the-scenes-with-foreign-keys/ for a few details)
• detach the partition into a specified archive schema
ALTER TABLE tablename DETACH PARTITION tablename_202401
INTO TABLE archive_schema.tablename_202401
• check to see if there are any previously detached partitions in the archive schema that can be removed. So, in this example, if I find a table called archive_schema.tablename_202312 then that is old enough (with this customer’s business rules) to qualify for deletion.
Now this oldest, archived partition will still be using the tablespaces that were explicitly created for it: tablename_DATA_202312 and tablename_INDEX_202312. But with the old partition being dropped these should be empty and targets for the Housekeeping that Drops empty tablespaces.
But it’s not empty; in the interim someone has created a couple of Indexes on some tables and they are now resident in tablename_DATA_202312
How to deal with this
First case: objects that are in the ‘wrong’ tablespace.
I’ve got a query that shows how many objects are in each tablespace. I’m not going to print it here as it’s quite sizeable; it must interrogate not just the SYSCAT views for Tables and Indexes but also DATAPARTITIONS and INDEXPARTITIONS. But if you sort the result set by number of objects in descending order, you can find Tablespaces that are ‘sparsely’ populated and, if you know the customers naming conventions, ones were the objects are misplaced.
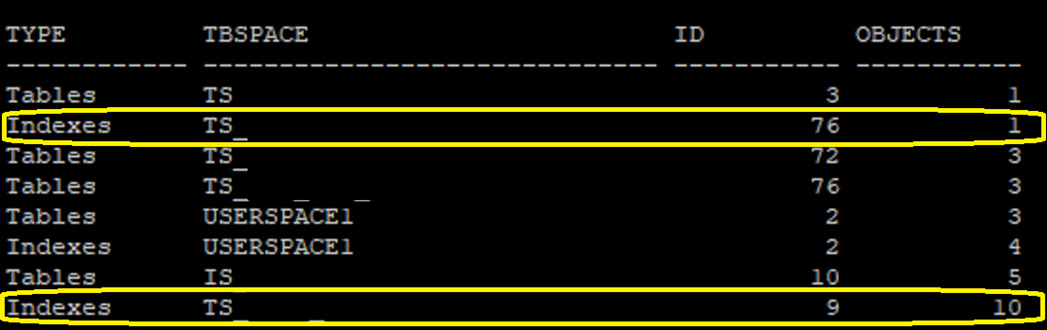
I’ve blacked-out the customers actual Tablespace names but you can see some begin ‘TS’ which are data tablespaces and some begin ‘IS’ which are for indexes. What I have ringed in this snapshot are a couple of data Tablespaces that contain indexes.
Locating the offending index isn’t too hard; running a query like this will give you the table and index
SELECT
CHAR(TabSchema,10) Schema
,CHAR(TabName,30) Table
,CHAR(IndName,20) Index
FROM SYSCAT.INDEXES
WHERE TBSpaceID=76
Then an execution of the Db2 Swiss Army Knife; ADMIN_MOVE_TABLE, can make sure that the table in question has its data and indexes in the correct tablespaces:
ADMIN_MOVE_TABLE(‘schema‘,tablename’,’TS_tablespace’,’IS_tablespace’,’LOB_tablespace‘,NULL,
NULL,NULL,NULL,NULL,’MOVE’)
Second case: a tablespace that should be empty but isn’t
In the course of looking at what our Housekeeping jobs do, I became aware of a tablespace that should have been identified as empty and then dropped. But it wasn’t, because it wasn’t empty. I have another query that is the inverse, in a sense, of the one I referred to in the previous section (again; too large to print here, but if anyone wants a copy, drop me a note). I gave it the name of the tablespace in question, and this is what it shows me (I’ve blacked out the full tablespace and table names).

The naming convention on this site indicates that the tablespace was one that was created to service a Partitioned Table but that it should only contain data pertaining to January 2020. But it has 2 indexes in it. Running my query to find the tables and indexes associated with a TBSpaceID, I find that the 2 indexes are the non-partitioned indexes for 2 Partitioned Tables.
This is a slightly different situation; when you create a Partition, you have the option of specifying a Data and an Index tablespace for that partition alone (something we frequently use, as we see often see a performance benefit). But if there was no default tablespace(s) defined for the table in the CREATE statement, then creating a non-partitioned index without a specified tablespace is invoking pot luck (if you define a partitioned index, it will go into the tablespace that you specified when you created the partition).
And that is what has happened here. You can check this by doing a db2look on the table(s) in question and looking at the definition for the non-partitioned index:
CREATE UNIQUE INDEX schema.index ON schema.table
( col1 ASC, col2 ASC, etc. )
NOT PARTITIONED IN "D_xxxxx_202001"
COMPRESS YES
INCLUDE NULL KEYS ALLOW REVERSE SCANS;
The good news here is that the solution doesn’t even involve a movement between tablespaces with ADMIN_MOVE_TABLE. You just need to DROP and then CREATE the index but specifying a ‘valid’ tablespace. Once that has been done for both indexes, the tablespace is genuinely empty and can be dropped.
Third case: more consistent tablespace sizes
This is just going to be some hard work; no magic wand on this one. The query I referred to in the first case; to find out how many objects are in each tablespace, can be re-ordered to show the ones with the most objects.

It’s fairly easy to see at a glance where the bottlenecks might be here. Trying to even out the number of objects in each tablespace would allow the BACKUP operations to process in parallel a bit more effectively. Of course, it’s not just the number of objects, it’s the size of the tablespace, but that seems to correspond fairly well:

(Note that old partition tablespace D_xxxx_202001 currently using a fair bit of storage. Another good argument for emptying it out and dropping it).
Conclusion
This is not cutting-edge technology, but it is a useful housekeeping exercise. It can give you some significant performance benefits and can also hand back some storage to the database. The BACKUP bottleneck should disappear once you upgrade to v12.1 and begin using Intra-Tablespace Parallelism, but a bit of regular maintenance on your tablespaces and their usage won’t go amiss, whatever version and edition you’re using.
Please contact me if you’d like me to share any of the queries referred to in this blog although, please bear in mind, they are supplied on a purely “as-is” basis and I can’t guarantee they will work in all environments.
E-mail: Mark.Gillis@triton.co.uk